TabPFN - Tabular Foundation Model

Tabular data
Tabular data는 행과 열(row, column)으로 이루어져 있는 표형 데이터를 말한다. 흔히 알고 있는 엑셀에서의 데이터나 Dataframe 형태로 이해할 수 있다.
- 행(row) : 관측값 또는 샘플 (observation)
- 열(column) : 변수 또는 특성 (feature)
얼뜻 보면 회귀분석에서의 Design matrix와 꽤나 유사한데, Tabular data는 Design matrix와는 다르게 각 열마다 데이터 타입이 다르다.
| 이름 | 나이 | 키(cm) | 성별 |
|---|---|---|---|
| 철수 | 25 | 175 | 남 |
| 영희 | 30 | 162 | 여 |
| 민수 | 22 | 180 | 남 |
위와 같이 tabular data는 한 행에 문자열, 숫자, boolean(남/여)와 같이 다양한 데이터 타입이 섞여있을 수 있다.
기존 딥러닝 모델을 사용할 수 있을까?
Tabular data는 각 열마다 데이터 타입이 다르고, 스케일도 다양하며, 결측치 (missing data), 불균형, outlier 등 데이터 자체가 가지고 있는 이질성(heterogeneity) 때문에 기존 딥러닝의 가정 (정규화되어 있는 균일한 데이터) 와 매우 떨어져 있을 수 밖에 없다. 또한 현재 대표적으로 사용되는 모델인 Transformer의 경우 데이터를 하나의 sequence로 보는데 이는 tabular data의 특징인 행과 열의 구조를 살리지 못하는 형태로 변화하는 경우가 많다.
따라서 기존의 지표를 보면 트리 기반의 모델 (XGBoost, Random forest, Gausian process)가 딥러닝 기법보다 좋은 지표를 보이는 경우가 많다. (Tabular Data: Deep Learning is Not All You Need 참고)
TabPFN
이 논문에서는 위와 같은 문제들을 해결하는 여러 방법을 제안하며 TabPFN 모델을 설계했다.
Data generation
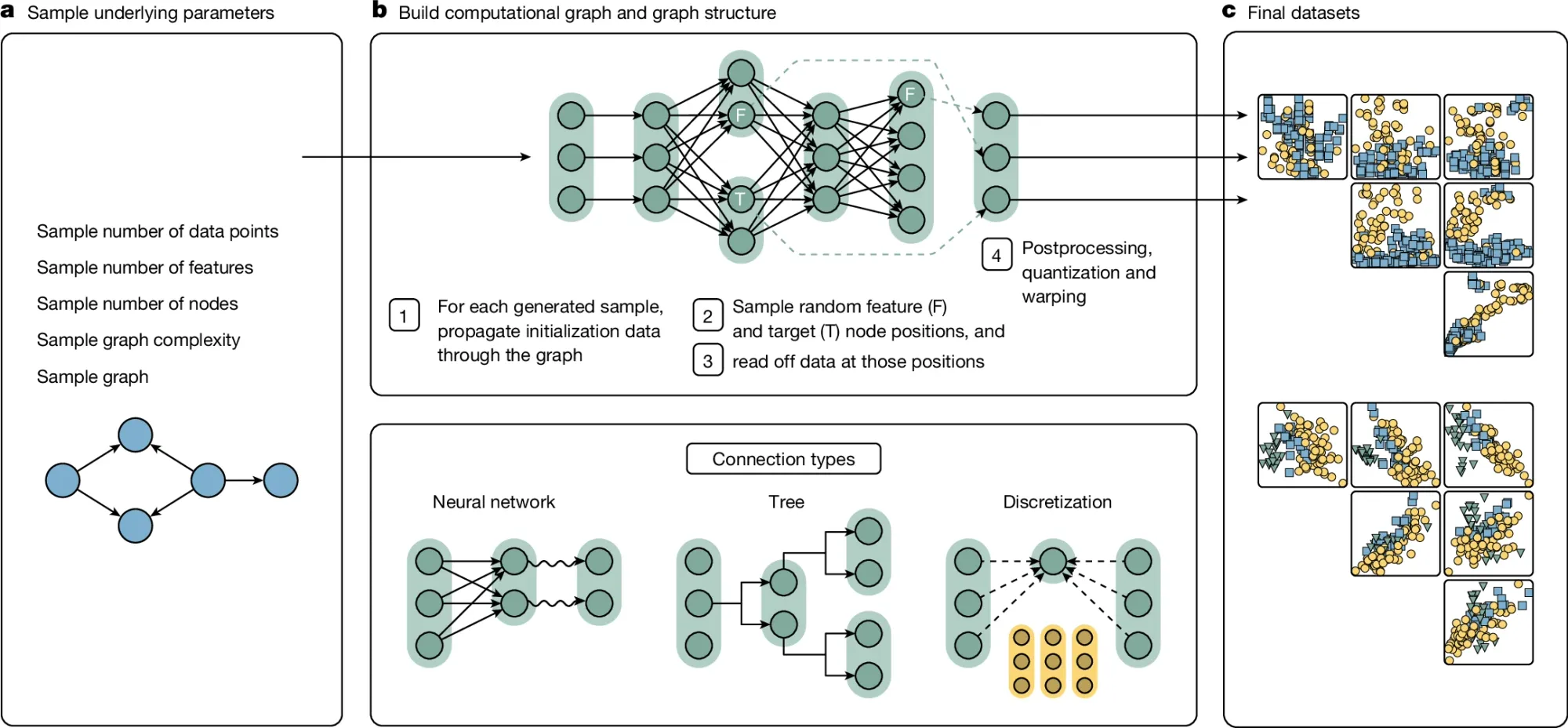
학습을 시키기 전, 학습을 하는 데이터를 직접 생성하는 부분이 다른 모델과는 다른 접근 방식을 가졌다. 이는 Structural Casual Model (SCM)에 기반하여 베이즈 기법을 활용해 현실에서 발생할 수 있는 모든 인과관계를 만들어 이를 기반으로 인공 데이터 (synthetic data)를 만드는 것으로 구현되었다. 논문에서는 이렇게 데이터를 만들게 된다면 위에서 언급한 문제점들 (결측치, 불균형, outlier)을 모두 포함된 데이터를 만들수 있다고 주장한다.
Pre-training
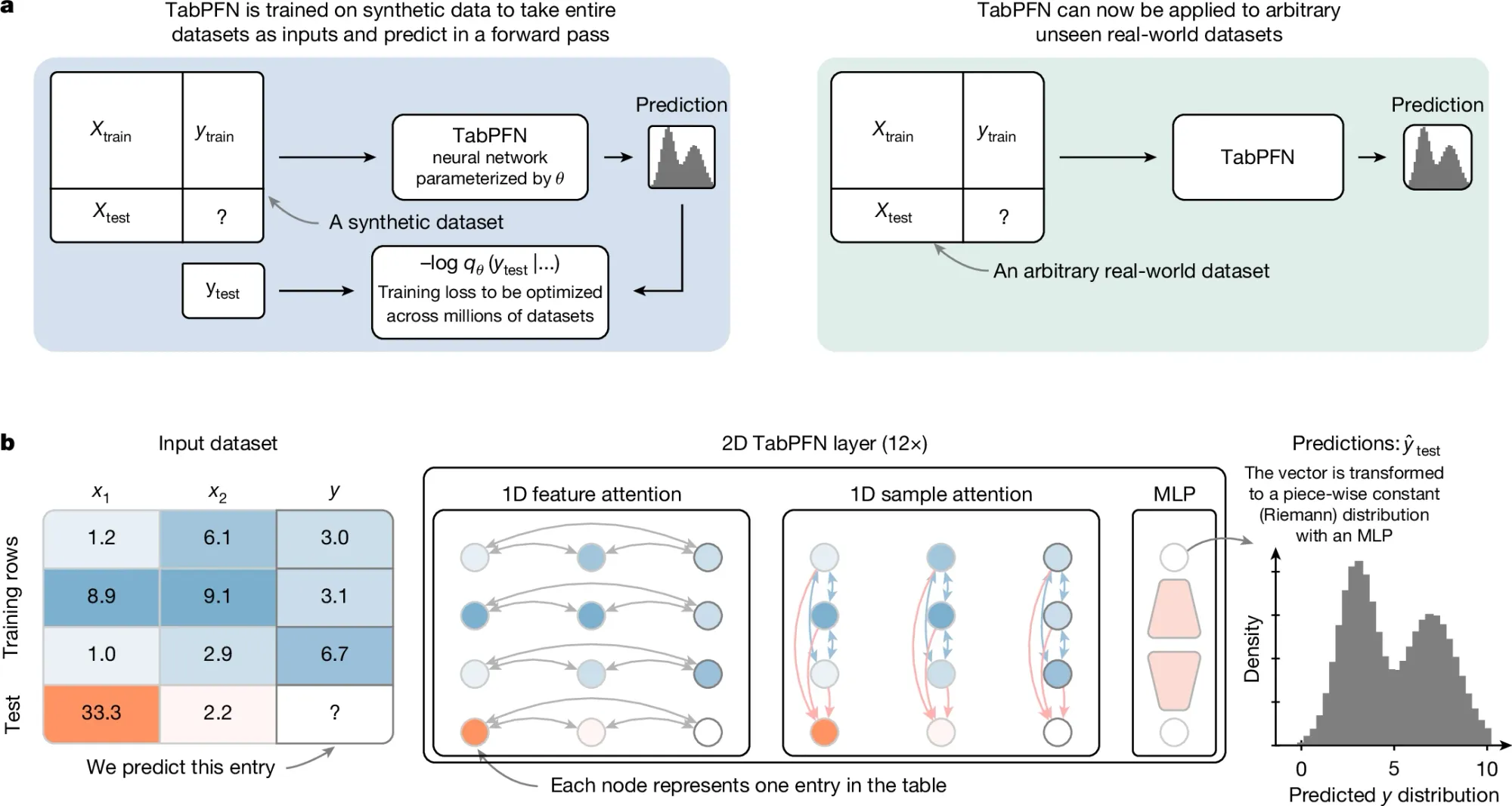
학습을 하는 과정에서는 하단 그림에서처럼 행에서의 attention(feature attention)과 열에서의 attention(sample attention) 모두 사용해 tabular data의 특징인 행과 열을 활용하기 위해 2D attention 기법을 활용한다.
궁금증
- 결국 Synthetic data를 만들어내는 것이 foundation model의 핵심이라고 보는데, 차원수가 높아지는 경우 복잡도가 높아지지 않을까? 현재 TabPFN 모델의 limitation이 10,000 training samples & 500 features인데 sample이 적고 feature가 많으면 어떻게 되는건가?
추가로 공부해야 할 주제들
- Structured Causal Model <- Synthetic data를 만드는 핵심 원리임
- PFN 논문 읽기
- Ensemble selection (Posthoc ensembling)